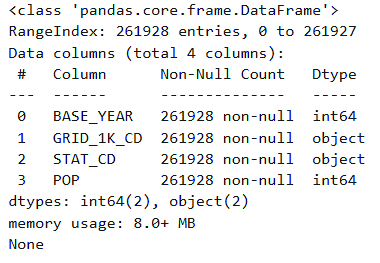
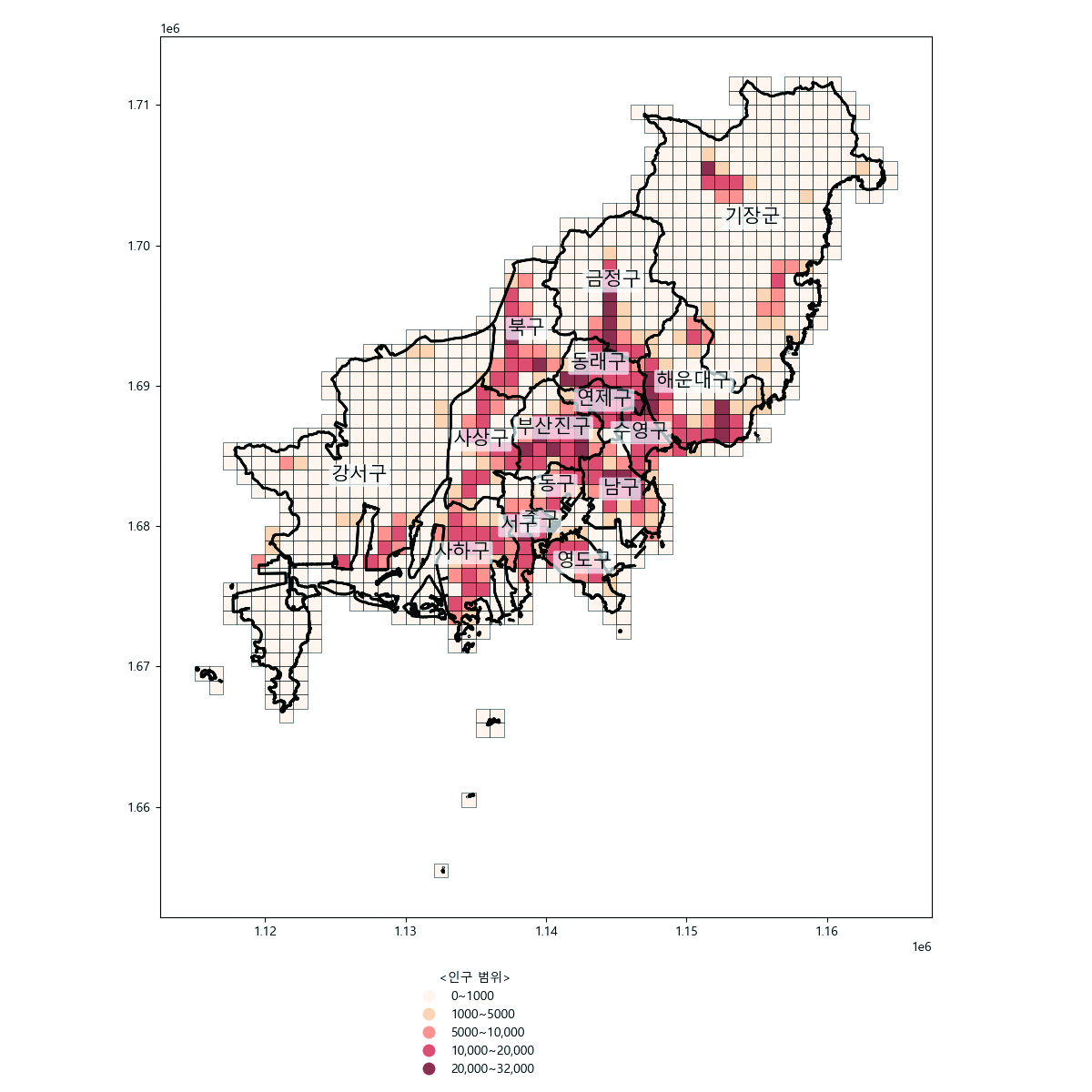
# 시각화 설정(그림과 축 설정)
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
# 격자 시각화(격자 경계 선은 연하게 설정)
grid_intersects.plot(column='POP_BINS', ax=ax, legend=True, cmap='OrRd',
edgecolor='black', linewidth=0.5, alpha=0.7)
# 부산시 경계 추가 (경계선만 보이도록 설정, 배경은 투명)
bord_sido.plot(ax=ax, color='none', edgecolor='black', linewidth=2)
# (추가) 시군구 경계를 추가하여 명확하게 분석하기
bord_sgg = gpd.read_file(prj_dir + '/' + 'bnd_sigungu_21_2024_2Q.shp')
bord_sgg.plot(ax=ax, color='none', edgecolor='black', linewidth=2)
bord_sgg['centroid'] = bord_sgg.geometry.centroid # 중심점 계산
for idx, row in bord_sgg.iterrows():
ax.text(row['centroid'].x, row['centroid'].y, row['SIGUNGU_NM'], fontsize=15, ha='center',
color='black', bbox=dict(facecolor='white', alpha=0.7, edgecolor='none',
boxstyle='round,pad=0.1'))
# 범례 위치 및 제목 설정
ax.get_legend().set_bbox_to_anchor((0.5, -0.05)) # 범례 위치 조정
ax.get_legend().set_title("<인구 범위>") # 범례 제목 설정
ax.set_title('<부산시 1km 격자 인구 분석>', fontsize=16) # 지도 제목 설정
# 레이아웃 조정 및 출력
plt.tight_layout() # 그래프 레이아웃이 겹치지 않도록 자동 조정
plt.savefig(prj_dir + '/' + '부산시 격자 인구 분석 지도.png')
plt.show() # 시각화 결과 화면에 출력

 부산시 인구수 현황 격자 분석(Python)
부산시 인구수 현황 격자 분석(Python)